
范式最主要的好处就是能够减少冗余存储,其他都是附加的,如消除异常(插入异常,更新异常和删除异常)
第一范式
表中的每一列都应该是不可再分的原子值,也就是说,每一个字段必须包含单一的值,而不能是一个复合值或多值属性.
让我们看看下面这个表的设计
| 员工表 |
|---|
| EmployeeID |
| departmentName |
| Name |
| Address |
| job |
| jobDescription |
| skill |
| departmentDescription |
从第一范式我们可以看出,表字段Address实际上还可以细分,我们不能直接了当的使用如“湖南省湘潭市雨湖区xxx”等作为地址,应该继续细分,这在我们以后需要统计xxx省,xxx市,xxx区的数据时很有帮助,所以上述表应该设计成下面这样
| 员工表 |
|---|
| EmployeeID |
| departmentName |
| Name |
| addressID |
| job |
| jobDescription |
| skill |
| departmentDescription |
| 员工地址表 |
|---|
| addressID |
| city |
| country |
| street |
| ... |
第二范式
表中所以非主键字段必须要和所有主键字段都有关联关系,第二范式一般在出现联合主键的时候分析
例如一个学生选课表:
里面有六个字段,分别是学号,名字,年龄,课程名称,成绩,学分。其中,学号和课程名词作为联合主键,但是我们会发现,姓名和年龄两个字段和课程并没有关联关系,学分和学号也没有关联关系,在因此,这些字段不适合放在同一张表,而应该分开,这个表的设计不符合第二范式。
我们继续分析,学分字段的数据就是冗余存储,不同的学号选择同一门课程的学分都是相同的,并不需要重复存储,同样,年龄和名字不会因为选择不同课程而会导致不同,存在冗余,随着学生年级的提示,课程的数量不断增加,这张表的冗余数据就会非常多
首先,学生和课程是多对多的关系,所以需要引入一张中间表,学生选课表
学生表:学号,姓名,年龄
课程表:课程id,课程名称,学分
选课表:学号,课程id,成绩
同理,我们再分析下面这个,使用EmployeeID和departmentName作为联合主键,发现其余字段并不符合第二范式的设计
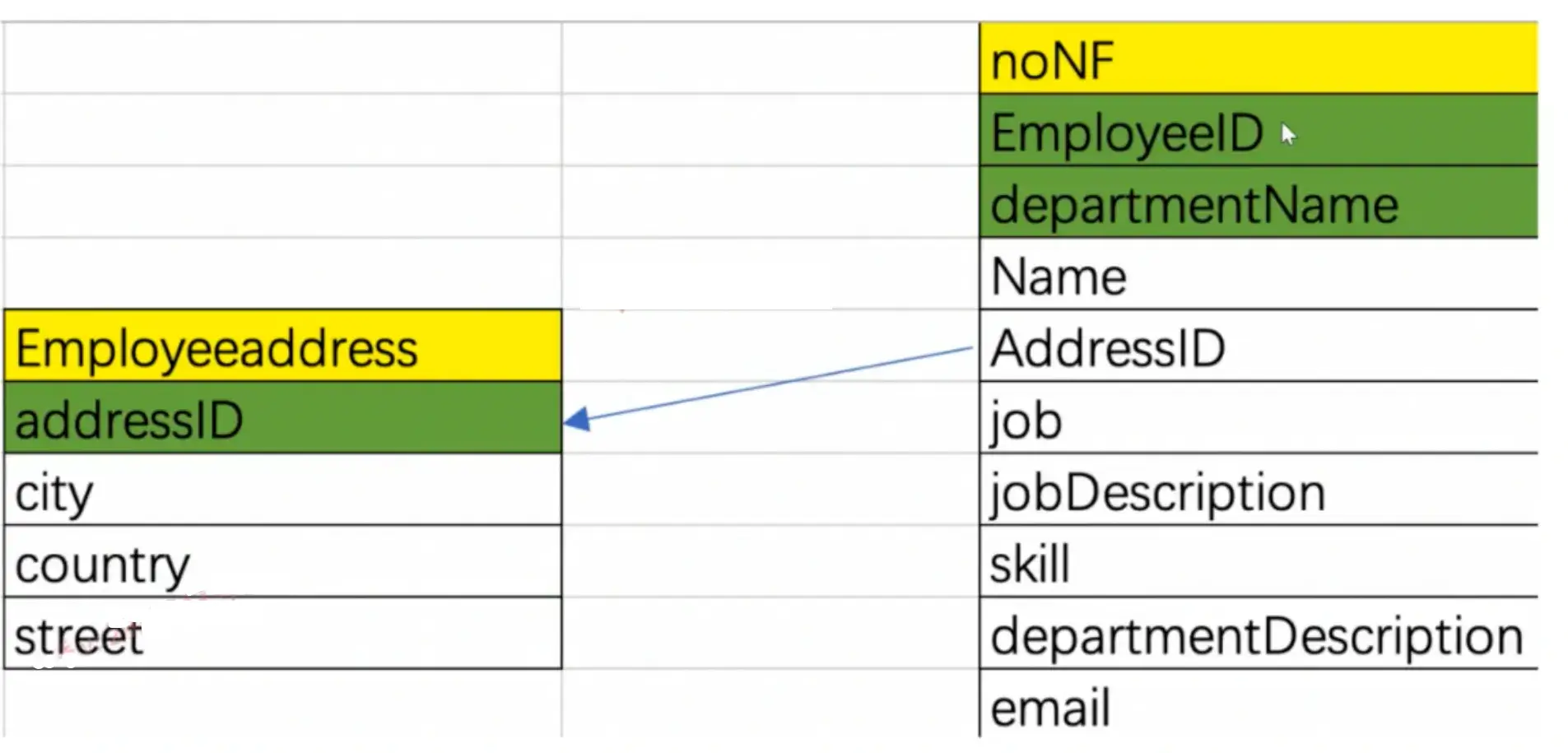
分析部门和员工的关系,是一对多的关系,一个部门有多个员工

第三范式
在单主键中,属性不依赖于其他非主属性,非主键部分必须依赖于主键

一般满足第三范式即可,还有其他范式,例如:BC范式,第四范式,但是这些范式会导致sql查询的复杂度,降低数据库的查询性能,需要权衡





